
I wrote this script to make a PDF file of the electronic training materials that I paid for. I don’t like to have to login and use their annoying E-Reader when doing my labs, so now I have a local copy of the study materials to work from.
This is just a quick and dirty hack but it gets the job done. I may try and refine it in the future if the need presents itself and time permits.
# !/usr/bin/perl
# List of variables you need to initialize accordingly
my $pdf = 'mypdf.pdf';
my $total_pages = 945;
my $path1 = "coverpage.xhtml?x=2qaVrNQfN0v3b8vS";
my $cookie = "PF=fOe5Q78waBjrCp3CeXnypU;";
my $cdckey = "cdcUniqueKey=gfjg956jf6c9a;";
my $gutc = "CP_GUTC=173.36.104.11.1520449009238480;";
my $ams1 = "AMCVS_B8D07FF4520E94C10A490D4C%40AdobeOrg=1;";
my $connsession = "connect.sess=s%3Aj%3A%7B%7D.%2FDXiRcvdPogANT%2BcuKheUyc2S5FHyqJ47GigS9Uw2TY;";
my $ams2 = "AMCV_B8D07FF4520E94C10A490D4C%40AdobeOrg=-227196251%7CMCIDTS%7C17598%7CMCMID%7C11239226229006569677119469477338917239%7CMCAID%7CNONE%7CMCOPTOUT-1520478615s%7CNONE;";
my $ccocookie = "ObSSOCookie=0utrBa%2F0YW8nZIEwEFmy0Fl1TIX3A5H8JCibnRJX0VP1KRSmNn6KSEjEvBc6p7kd21l6Ru82MHGoRL8BvqA7qhSvBg6zaUX3mvFnfxSkQP%2Fa%2FfKmQqXwFS%2BV%2F1wbenuk%2BS1sZh%2ByMDCKafWOihqZT6klQFr11%2FMF3uaxn59HnY%2BLFNJv5c26bmgWcWMJ0YKpMNSqxXLfHW11VmAMjrLkLynlFHVZfVhk6dXy3un7HAEveNY%2Bxswr%2FESCVUOUZl4XhI28bNDCLc1OQVfBmiVY9DT2YjuR3j3rYbrBdxj%2BmetyTt5GhAaSt%2B%2FZuI%2Bn6v2VxyTTwAEDVezE3KB%2FduMOVkycbrNk73hhuDUVp9GRM21oEv1WfAFxcbyqZWrFUkuACK%2BBGfQneSjHPOm0dsW2VQ%3D%3D;";
my $ac = "ac_uid=9Ete598p1ws9Z6W8;";
my $sessid ="SESSION=c05844e4-3a6e-4b82-b3bb-d070e2b14ddf;";
my $course ="229";
my $lan = "en";
my $version ="4.0.0";
# No need to change anything below here
my $counter = 1;
my $current_page = 1;
my $str1 = "html_list";
my $string ="URL";
my @array;
while ($current_page <= $total_pages) {
push @array, $counter.".htm ";
$counter += 1;
my $http = "'https://learningspace.cisco.com/dkitserver/books/$course/$lan/$version/extracted/html/$path1&isLatest=true&pageNumber=$current_page'";
my $http2= ' -H '."'Cookie: $cookie $cdckey $ams1 $ams2 $gutc $ccocookie $connsession $ac $sessid'";
$string = $http.$http2;
` curl $string -o $current_page'.htm' ` ;
$current_page += 1;
} # end while
$str1 = join('', @array) ;
# may need to play with the delay if your missing content and your sure it's in the htm file
` wkhtmltopdf --dpi 300 --javascript-delay 60000 $str1 $pdf ` ;
Web Structure for the script above.
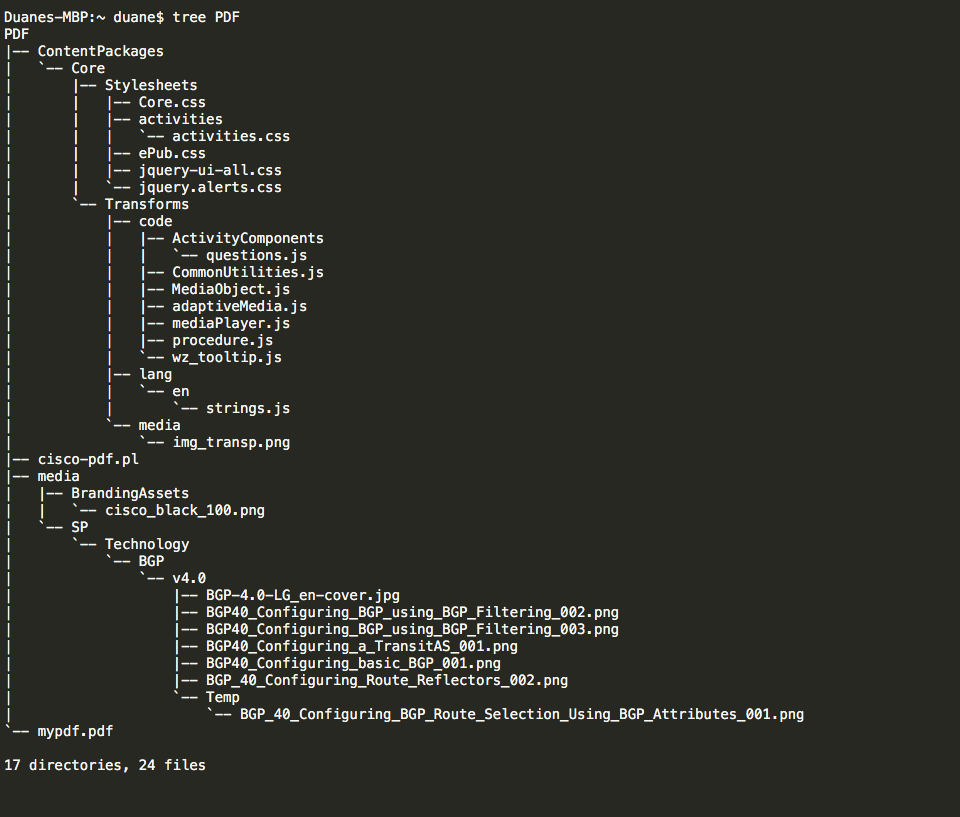
EDIT: Cisco has made some changes to their e-reader program so that this script requires an update. The main thing that they did was obfuscate the page names so that it’s not trivial to parse through the content. I’ll need to modify the script to account for these dynamically allocated names and add the Cloudflare info that they are also now looking for.